A Brief Guide of (RESTful) SOA, Part I
Many say that XML SOAP WS-\* suck and SOA is over or becoming profit tool for big consultant companies. But I would say: SOA is not evil, IBM is. Look at these principles of SOA:
- reuse, granularity, modularity, composability, componentization and interoperability.
- standards-compliance (both common and industry-specific).
- services identification and categorization, provisioning and delivery, and monitoring and tracking.
– Wikipedia Service-oriented architecture
All these are perfect software architectural styles(well, except those words your spell checker complains), our best dream. These can’t be wrong. The problem is in the implementations. Fortunately the rises of RESTful services on the open web prove that the spirit of SOA can really matters. Maybe one day similar architecture and implementation will eventually change enterprise computing in return.
I always believe the service-oriented architecture will be the future of massive distributed software system. And RESTful services will replace web sites and eventually become the main body of the Internet. So I often think about how to help approaching it. I know that lots of people want to implement RESTful style services in their system (though they may not know what for). What they need is a brief and clean(maybe not extremely accurate and complete) guideline when practicing RESTful services. It can help to make things right and avoid traps such as using HTTP request as RPC protocol - it can be used as RPC protocol but it’s not RESTful and cannot provide key benefits which REST want to apply.
Here it is. Below I’ll list a brief guide which can help you find the path, as in the Matrix movies Morpheus told Neo about the Oracle:
“Try not to think of it in terms of right and wrong. She is a guide. She can help you to find the path.”
– Morpheus, The Matrix Movie
Don’t get me wrong, I tried my best to keep it right and accurate, but it’s very complicated and cannot be completely covered and explained while keep it simple and readable. If you want more conceptual or technical details, I’ll leave you a bunch of references.
Even we have all these compromises this guide will still be too long for a single blog post, so I will divide it into 3 parts and complete them within a month or two.
NOTE: In this guide, service oriented architecture and RESTful architecture style are nearly the same concept. I will use the term RESTful from here on.
Level I: Basic Definitions and Rules
1.1 Objectives
First of all you should know the purpose, why your service should follow the RESTful style and what benefits you can get. So when you get some trouble making architectural decision you can use these high level objectives to test all options: which one is the best for these objective?
Decoupled: Services are decoupled from each other and from service consumers. All services and service consumers can evolve independently. Service consumers can integrate different services more easily. For example, You can provide a good service interface and an ugly(but working) implementation, then improve the implementation before the service becoming very popular and requests crashing down your server.
More scalable and flexible: Services can be more easily changed, scaling, tuning, refactoring. Even when business changes, the services can be more easily changed to match the new business while keep compatibility with old business(clients).
Easier integration and mash-up: All services have uniform interfaces and similar behaviors. Clients to same service are exchangeable. Service integration, inter-op and mash-up are easier to implement.
1.2 Core Principles
RESTful style requires:
A client-server model which provides better separation of concerns(SoC). The service provider(server) need not to know the user interfaces and HCIs while the service consumer(client) need not to know the data storage and infrastructure, which give far more opportunity for reusing and changing without pain.
Stateless: No client state or context will be stored on server between requests. Each request should contain all information necessary for the server to service the request, and any session state should be held in the client.
Cacheable: Clients can cache responses. Furthermore, server and client should have a protocol to define caching strategy: which response can be cached, for how long or till what happens, to prevent clients reusing inappropriate cached data.
Layered: System is layered and no cross layer info exposures. Client cannot tell whether it is directly connecting to the service provider or some intermediate layer, giving the interface is the same.
Uniform interface which makes server and client decoupled on implementation, enables each part to evolve independently. It’s the most practical part so we will discuss it separately below.
All these 5 rules are required. If a service violet any of them it cannot be called ‘RESTful’ - and more important, cannot get the benefits which RESTful styles declare to provide. So understanding all of them is the most important pre-requisite.
Level II: Define Your System
Before defining the APIs you should define your system first. You can do it through 2 steps:
2.1 Business Abstraction
Business abstraction is very important but hard to routinize. And it’s mostly beyond the realm which RESTful style can control. You should find the essential business concepts and make smart abstraction for high flexibility and extensibility. Yet we still can have some guideline. Probably will not solve the most difficult part of the problem but still give some help.
Find business objects. When the system complete, every business objects exposed to the public will be presented as an URI. Clients can issue POST GET PATCH/PUT DELETE requests to the URI to CRUD(create/read/update/delete) correlated object. So any objects you want to exposed to the public for clients to do the CRUD things you should make them in the business object model, as essential objects.
Define the relations. Next step is to define the relations between objects. The classical entity-relation analysis methodology is very good at that. Find all 1-1 1-* *-* etc. relations and make them clearly documented.
The object graph. It’s optional but very useful. In most case build an object graph at this stage will help to clarify many potential obscure concepts in the business object model. Try fill some real data in the object model and understand the order and constrains of each operation. Refine the object-relation model if necessary.
2.2 Define Response Objects
Now define some response data formats. Some may feel weird to do that in such early stage but trust me it’s the best path you can choose.
Firstly you should know that as highly recommended by RESTful style, the object and its representation are isolated. The same object can have many different representations which can be designated by the clients when issuing the request.
Second, do NOT try to invent your own representation type system, just use the well defined exist Internet media types(originally called MIME types), as defined in RFC 2046. Every system on the Internet have built-in support to it and all developers are familiar with text/html application/json image/jpeg multipart/form-data etc.
Now define the core response objects, in JSON format. Normally when clients request for a business object e.g. GET /user/:uid the service will return a user object in JSON format(application/json). JSON has become the most widely used cross platform data exchange format these days. You can provide support for responses in other media types such as text/html application/pdf later. And here are some best practices for that:
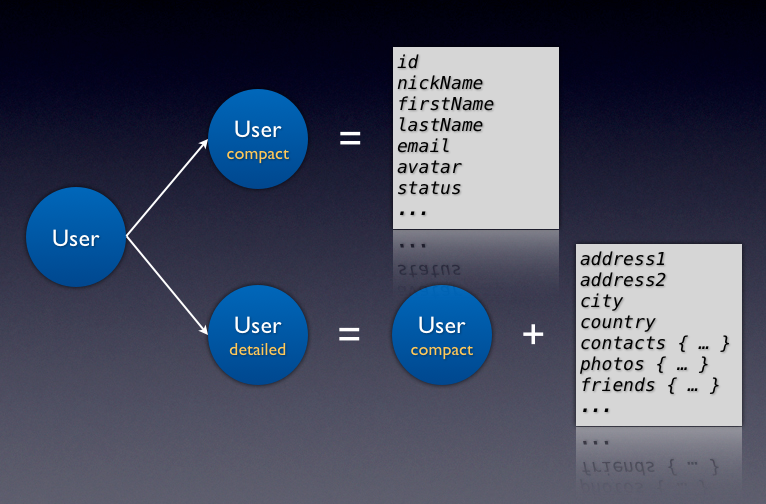
Separate core attributes and other attributes. In most cases you should provide two versions of the same object type:
- The compact version which only contains the most frequently used core attributes of the object and very lightweight(for bandwidth and for parsing), which is often used embedded within other object or in arrays.
- The detailed version which contains all fields in the compact version plus more detail info, such as attributes not so frequently used and other objects related to this object, which is often used for clients retrieving a single object.
Below is a demo:
Use embedded object not the object id. Assuming you are working on a online comment system and you have objects user and post. In post object there is an attribute author pointing to a user object. You should embedded a compact version of user object in the post object instead of only the user id. As shown in the snippet below:
// BAD style
post: {
id: 10010,
title: "Hello",
body: "Hi there!",
createdAt: 1333250513,
author: 1,
...
}
// GOOD style
post: {
id: 10010,
title: "Hello",
body: "Hi there!",
createdAt: 1333250513,
author: {
id: 1,
nickName: "soulhacker",
avatar: "",
status: "Doing something matters",
online: true,
...
},
...
}
In many cases this strategy will bring data redundancy but make client-side parsing and handling more convenient. Server-side implementation will be more structural and reusable as well.
Normalize array representation so clients can parse them using one single handler. Below is return data of some user search API:
users: {
total: 126, // totally 126 users match this request
count: 10, // but we just return the first 10 records
items: [
{
... // a compact user object inside
}
... // 9 more user objects here
]
}
Client-side handling can be very simple and reusable. Snippet below shows how it goes in Ruby:
# Utility methods
def countFromJSONCollection(data)
# data is a JSON object return from JSON.parse(response)
return 0 if data == nil
total = data['total']
count = data['count']
return Integer(total), Integer(count)
end
def itemsFromJSONCollection(data, c)
# c is a class with class method named fromJSON to init object
return nil if c == nil or data == nil or data['items'] == nil
count = data['items'].size
array = Array.new(count) { |i| c.fromJSON(data['items'][i]) }
end
class Collection
attr_accessor :total, :count, :items
def self.fromJSON(data=nil, c=nil)
return nil if data == nil or c == nil
coll = self.new
coll.total, coll.count = countFromJSONCollection(data)
coll.items = itemsFromJSONCollection(data, c)
coll
end
end
Explicitly mark all required and optional fields. Not all data are equally important. As part of the protocol service providers should let clients know exactly which ones are optional. But remember HTTP is not a reliable communication protocol and the network status is even more complicated in mobile Internet, clients should do all error-tolerant things even for those fields marked as required.
To be continued…
In the following parts we will talk about how to define the API specs and give general info about concerns in implementation.